ListenFormer.github.io
ListenFormer: Responsive Listening Head Generation with Non-autoregressive Transformers
CodeAbstract
As one of the crucial elements in human-robot interaction, responsive listening head generation has attracted considerable attention from researchers. It aims to generate a listening head video based on a speaker audio and video as well as a reference listener image. However, existing methods exhibit two limitations: 1) their generation capability is limited, resulting in generated videos that are far from real ones in terms of emotional expression and diversity, and 2) they mostly employ non-autoregressive generation methods, unable to mitigate the risk of error accumulation. To tackle these issues, we propose Listenformer that leverages the powerful temporal modeling capability of transformers for generation, and can perform non-autoregressive prediction with the proposed two-stage training method. To fully utilize the information from the speaker inputs, we designed an audio-motion attention fusion module, which improves the correlation of audio-motion features for accurate response. Additionally, a novel decoding method is proposed for Listenformer, demonstrating both excellent computational efficiency and effectiveness. Extensive experiments demonstrate that Listenformer outperforms the existing state-of-the-art methods on ViCo and L2L datasets. And a perceptual user study shows the comprehensive performance of our method in generating diversity, identity preserving, speaker-listener synchronization, and attitude matching.
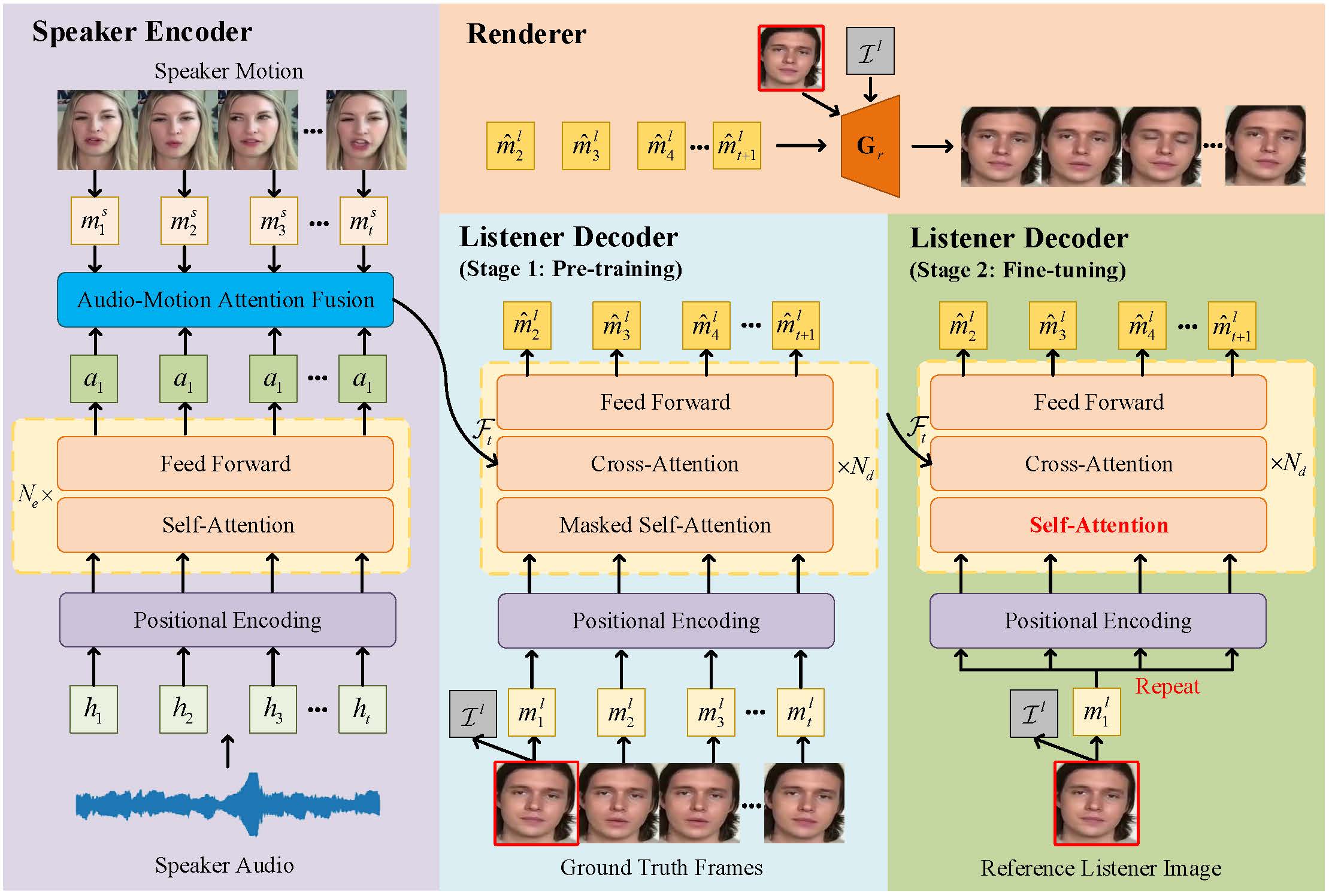
Method
ListenFormer can generate a listening head video based on a speaker audio and video as well as a reference listener image.